Redis分布式架构
Redis 是一个高性能的基于内存实现的K-V存储数据库 。
性能极高,Redis能读的速度是110000次/s,写的速度是81000次/s 。
支持持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
多种数据类型,同时还提供list,set,zset,hash等数据结构的存储。
支持主从复制,自动同步,可实现读写分离。
丰富的特性,支持pub/sub,key过期策略,事务,支持多个DB等。
基于内存存储,单机容量有限。
重启会加载磁盘缓存到内存,这期间不能提供服务。
主从复制采用全量复制,这个过程会占用更多内存和网络资源。
从源码安装
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# download
wget https://download.redis.io/releases/redis-6.2.5.tar.gz
tar xzf redis-6.2.5.tar.gz
cd redis-6.2.5
make
# run redis-server
src/redis-server
# test
src/redis-cli
redis> set foo bar
OK
redis> get foo
"bar"
Ubuntu 安装
1
2
3
sudo add-apt-repository ppa:redislabs/redis
sudo apt-get update
sudo apt-get install redis
Mac 安装
先引入jar包
1
2
3
4
5
<dependency>
<groupId> redis.clients</groupId>
<artifactId> jedis</artifactId>
<version> 2.9.0</version>
</dependency>
JAVA 代码调用实例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
public class JedisSingleTest {
public static void main ( String [] args ) throws IOException {
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig ();
jedisPoolConfig . setMaxTotal ( 20 );
jedisPoolConfig . setMaxIdle ( 10 );
jedisPoolConfig . setMinIdle ( 5 );
// timeout,这里既是连接超时又是读写超时,从Jedis 2.8开始有区分connectionTimeout和soTimeout的构造函数
JedisPool jedisPool = new JedisPool ( jedisPoolConfig , "192.168.0.60" , 6379 , 3000 , null );
Jedis jedis = null ;
try {
//从redis连接池里拿出一个连接执行命令
jedis = jedisPool . getResource ();
System . out . println ( jedis . set ( "single" , "zhuge" ));
System . out . println ( jedis . get ( "single" ));
} catch ( Exception e ) {
e . printStackTrace ();
} finally {
//注意这里不是关闭连接,在JedisPool模式下,Jedis会被归还给资源池。
if ( jedis != null )
jedis . close ();
}
}
}
管道可以一次发送多个命令给Redis服务,减少网络开销,如果前面的命令执行失败,后面的命令会继续执行,不会被影响,最后把所有命令的执行结果一次返回。
1
2
3
4
5
6
7
8
9
Pipeline pl = jedis . pipelined ();
for ( int i = 0 ; i < 10 ; i ++ ) {
pl . incr ( "pipelineKey" );
pl . set ( "zhuge" + i , "zhuge" );
//模拟管道报错
// pl.setbit("zhuge", -1, true);
}
List < Object > results = pl . syncAndReturnAll ();
System . out . println ( results );
LUA 脚本可以代替Redis的事务执行,要么所有命令都执行成功,要么都失败,是原子性的,也可以减少网络开销。
在Redis控制台执行:
1
2
3
4
5
127.0.0.1:6379> eval "return {KEYS[1],KEYS[2],ARGV[1],ARGV[2]}" 2 key1 key2 first second
1) "key1"
2) "key2"
3) "first"
4) "second"
在代码中使用:
模拟减库存操作,如果后面执行失败,减掉的库存会回滚。
1
2
3
4
5
6
7
8
9
10
11
jedis . set ( "product_stock_10016" , "15" ); //初始化商品10016的库存
String script = " local count = redis.call('get', KEYS[1]) " +
" local a = tonumber(count) " +
" local b = tonumber(ARGV[1]) " +
" if a >= b then " +
" redis.call('set', KEYS[1], a-b) " +
" return 1 " +
" end " +
" return 0 " ;
Object obj = jedis . eval ( script , Arrays . asList ( "product_stock_10016" ), Arrays . asList ( "10" ));
System . out . println ( obj );
Redis缓存达到最大内存限制时会执行淘汰策略,如下命令设置最大内存。
如下配置key淘汰策略,默认noeviction(拒绝请求)。
1
maxmemory-policy noeviction
全部配置参数:
noeviction 达到内存限制时返回错误,直接拒绝,del命令除外,是Redis的默认策略。allkeys-lru 尝试删除最近最少使用的,也就是优先驱逐最长时间没使用的。volatile-lru 尝试删除最近最少的使用的,但仅限设置了过期时间的key。allkeys-random 随机驱逐key。volatile-random 随机驱逐key, 但仅限设置了过期时间的key。volatile-ttl 驱逐设置了过期时间的key, 优先驱逐生存期较短的。allkeys-lfu 优先驱逐最近最不常使用的,也就是优先驱逐一定时间内使用次数最少的,4.1 新增的。volatile-lfu 优先驱逐最近最不常使用的,但仅限设置了过期时间的key,4.1 新增的。
假如用一条条执行 SET的方式插入百万级的数据量,虽然每条命令执行很快,但是网络来来回回折腾带来的开销也不容小觑,为了执行海量数据批量导入,可以结合redis管道完成。
首先将要导入的数据以命令的方式写入到文件中,如下:
/tmp/big-data.txt
1
2
3
4
SET name zhangsan
SET name1 lisi
SET name2 wangwu
SET name3 zhaoliu
然后执行以下命令导入
1
cat big-data.txt | redis-cli --pipe
执行结果
1
2
3
All data transferred. Waiting for the last reply...
Last reply received from server.
errors: 0, replies: 1000000
keys * 会一次返回匹配到的所有key, 当数据量大时要慎用,避免阻塞redis。
实例1:查询所有的key
1
2
3
4
5
127.0.0.1:6379> keys *
1) "name3"
2) "name1"
3) "name2"
4) "name"
实例2:查询所有前缀为name的key
1
2
3
4
5
127.0.0.1:6379> keys name*
1) "name3"
2) "name1"
3) "name2"
4) "name"
scan 遍历可以做到分页遍历,数据量大是比较合适,每次请求会返回下次一的游标,直达游标为0结束,但是在遍历过程中如果有key新增或删除可能出现新重复数据等情况,使用时要注意。
命令格式
1
SCAN cursor [ MATCH pattern] [ COUNT count]
实例:扫描key前缀为name的元素,每次返回2条。
1
2
3
4
5
127.0.0.1:6379> scan 0 match name* count 2
1) "1"
2) 1) "name3"
2) "name2"
3) "name"
1
2
3
4
127.0.0.1:6379> scan 1 match name* count 2
1) "0"
2) 1) "name1"
127.0.0.1:6379>
当返回的 cursor 为0时结束。
根据配置规则redis 会以生生二进制文件dump.rdb的方式持久化数据到磁盘,每次持久化会生成一个新的文件覆盖旧的文件,默认是开启的,配置方法如下所示。
开启rdb模式
1
2
3
save 900 1
save 300 10
save 60 10000 # 60s内有10000个key被改动则触发rdb持久化
关闭RDB只需要将所有的save保存策略注释掉即可。
还可以手动执行命令生成RDB快照,进入redis客户端执行命令save 或bgsave 可以生成dump.rdb文件, 每次命令执行都会将所有redis内存快照到一个新的rdb文件里,并覆盖原有rdb快照文件。save 会同步执行,阻塞客户端的操作,bgsave会fork一个子进程处理异步处理。
aof 是以记类似日志的方式持久化,默认是关闭的,需要执行以下命令开启。
开启aof模式
aof 策略配置
1
2
3
appendfsync always # 每次有新命令追加到 AOF 文件时就执行一次 fsync ,非常慢,也非常安全。
appendfsync everysec # 每秒 fsync 一次,足够快,并且在故障时只会丢失 1 秒钟的数据。
appendfsync no # 从不 fsync ,将数据交给操作系统来处理。更快,也更不安全的选择。
aof 重写
多次修改同一个key的值后,经过aof重写会只保留最后一次修改的命令,这样可以保持aof文件只保留有效的命且减少占用存储空间,默认自动开启。
1
2
auto-aof-rewrite-percentage 100 # aof文件自上一次重写后文件大小增长了100%则再次触发重写
auto-aof-rewrite-min-size 64mb # aof文件至少要达到64M才会自动重写,文件太小恢复速度本来就 很快,重写的意义不大
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
1、复制一份redis.conf文件
2、将相关配置修改为如下值:
port 6380
pidfile /var/run/redis_6380.pid # 把pid进程号写入pidfile配置的文件
logfile "6380.log"
dir /usr/local/redis-5.0.3/data/6380 # 指定数据存放目录
# 需要注释掉bind
# bind 127.0.0.1(bind绑定的是自己机器网卡的ip,如果有多块网卡可以配多个ip,代表允许客户端通过机器的哪些网卡ip去访问,内网一般可以不配置bind,注释掉即可)
3、配置主从复制
replicaof 192.168.0.60 6379 # 从本机6379的redis实例复制数据,Redis 5.0之前使用slaveof
replica-read-only yes # 配置从节点只读
4、启动从节点
redis-server redis.conf
5、连接从节点
redis-cli -p 6380
6、测试在6379实例上写数据,6380实例是否能及时同步新修改数据
7、可以自己再配置一个6381的从节点
如果你为master配置了一个slave,不管这个slave是否是第一次连接上Master,它都会发送一个PSYNC 命令给master请求复制数据。
master收到PSYNC命令后,会在后台进行数据持久化通过bgsave生成最新的rdb快照文件,持久化期间,master会继续接收客户端的请求,它会把这些可能修改数据集的请求缓存在内存中。当持久化进行完毕以后,master会把这份rdb文件数据集发送给slave,slave会把接收到的数据进行持久化生成rdb,然后再加载到内存中。然后,master再将之前缓存在内存中的命令发送给slave。
当master与slave之间的连接由于某些原因而断开时,slave能够自动重连Master,如果master收到了多个slave并发连接请求,它只会进行一次持久化,而不是一个连接一次,然后再把这一份持久化的数据发送给多个并发连接的slave。
无法实现自动故障转移,主节点挂了从节点需要手动顶上去。
sentinel哨兵是特殊的redis服务,不提供读写服务,主要用来监控redis实例节点。 哨兵架构下client端第一次从哨兵找出redis的主节点,后续就直接访问redis的主节点,不会每次都通过 sentinel代理访问redis的主节点,当redis的主节点发生变化,哨兵会第一时间感知到,并且将新的redis 主节点通知给client端(这里面redis的client端一般都实现了订阅功能,订阅sentinel发布的节点变动消息)
redis 哨兵架构搭建步骤
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
1、复制一份sentinel.conf文件
cp sentinel.conf sentinel-26379.conf
2、将相关配置修改为如下值:
port 26379
daemonize yes
pidfile "/var/run/redis-sentinel-26379.pid"
logfile "26379.log"
dir "/usr/local/redis-5.0.3/data"
# sentinel monitor <master-redis-name> <master-redis-ip> <master-redis-port> <quorum>
# quorum是一个数字,指明当有多少个sentinel认为一个master失效时(值一般为:sentinel总数/2 + 1),master才算真正失效
sentinel monitor mymaster 192.168.0.60 6379 2 # mymaster这个名字随便取,客户端访问时会用到
3、启动sentinel哨兵实例
src/redis-sentinel sentinel-26379.conf
4、查看sentinel的info信息
src/redis-cli -p 26379
127.0.0.1:26379>info
可以看到Sentinel的info里已经识别出了redis的主从
5、可以自己再配置两个sentinel,端口26380和26381,注意上述配置文件里的对应数字都要修改
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
public class JedisSentinelTest {
public static void main ( String [] args ) throws IOException {
JedisPoolConfig config = new JedisPoolConfig ();
config . setMaxTotal ( 20 );
config . setMaxIdle ( 10 );
config . setMinIdle ( 5 );
String masterName = "mymaster" ;
Set < String > sentinels = new HashSet < String > ();
sentinels . add ( new HostAndPort ( "192.168.0.60" , 26379 ). toString ());
sentinels . add ( new HostAndPort ( "192.168.0.60" , 26380 ). toString ());
sentinels . add ( new HostAndPort ( "192.168.0.60" , 26381 ). toString ());
//JedisSentinelPool其实本质跟JedisPool类似,都是与redis主节点建立的连接池
//JedisSentinelPool并不是说与sentinel建立的连接池,而是通过sentinel发现redis主节点并与其建立连接
JedisSentinelPool jedisSentinelPool = new JedisSentinelPool ( masterName , sentinels , config , 3000 , null );
Jedis jedis = null ;
try {
jedis = jedisSentinelPool . getResource ();
System . out . println ( jedis . set ( "sentinel" , "zhuge" ));
System . out . println ( jedis . get ( "sentinel" ));
} catch ( Exception e ) {
e . printStackTrace ();
} finally {
//注意这里不是关闭连接,在JedisPool模式下,Jedis会被归还给资源池。
if ( jedis != null )
jedis . close ();
}
}
}
引入依赖的jar包
1
2
3
4
5
6
7
8
9
<dependency>
<groupId> org.springframework.boot</groupId>
<artifactId> spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId> org.apache.commons</groupId>
<artifactId> commons-pool2</artifactId>
</dependency>
配置连接信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
server :
port : 8080
spring :
redis :
database : 0
timeout : 3000
sentinel : #哨兵模式
master : mymaster #主服务器所在集群名称
nodes : 192.168.0.60 : 26379 , 192.168.0.60 : 26380 , 192.168.0.60 : 26381
lettuce :
pool :
max-idle : 50
min-idle : 10
max-active : 100
max-wait : 1000
使用代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
@RestController
public class IndexController {
private static final Logger logger = LoggerFactory . getLogger ( IndexController . class );
@Autowired
private StringRedisTemplate stringRedisTemplate ;
/**
* 测试节点挂了哨兵重新选举新的master节点,客户端是否能动态感知到
* 新的master选举出来后,哨兵会把消息发布出去,客户端实际上是实现了一个消息监听机制,
* 当哨兵把新master的消息发布出去,客户端会立马感知到新master的信息,从而动态切换访问的masterip
*
* @throws InterruptedException
*/
@RequestMapping ( "/test_sentinel" )
public void testSentinel () throws InterruptedException {
int i = 1 ;
while ( true ){
try {
stringRedisTemplate . opsForValue (). set ( "zhuge" + i , i + "" );
System . out . println ( "设置key:" + "zhuge" + i );
i ++ ;
Thread . sleep ( 1000 );
} catch ( Exception e ){
logger . error ( "错误:" , e );
}
}
}
}
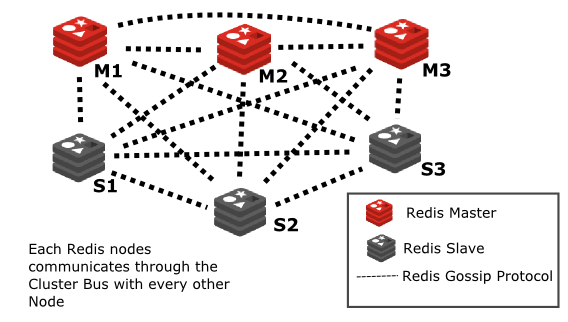
虽然实现了自动故障转移,主节点挂了从节点会自动顶上去,但集群中只能有一个主节点提供服务,无法适应大量的数据存储,一个节点的内存毕竟的有限的,下面的集模式可以改进次问题,Redis集群模式可以实现数据分片,把不同的数据存储在不同的节点上,理论上可以做到无限大内存。
Redis 集群至少需要3个主节点,一般需要给每个主节点配一个从节点。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
第一步:在第一台机器的/usr/local下创建文件夹redis-cluster,然后在其下面分别创建2个文件夾如下
(1)mkdir -p /usr/local/redis-cluster
(2)mkdir 8001 8004
第一步:把之前的redis.conf配置文件copy到8001下,修改如下内容:
(1)daemonize yes
(2)port 8001(分别对每个机器的端口号进行设置)
(3)pidfile /var/run/redis_8001.pid # 把pid进程号写入pidfile配置的文件
(4)dir /usr/local/redis-cluster/8001/(指定数据文件存放位置,必须要指定不同的目录位置,不然会丢失数据)
(5)cluster-enabled yes(启动集群模式)
(6)cluster-config-file nodes-8001.conf(集群节点信息文件,这里800x最好和port对应上)
(7)cluster-node-timeout 10000
( 8) # bind 127.0.0.1(bind绑定的是自己机器网卡的ip,如果有多块网卡可以配多个ip,代表允许客户端通过机器的哪些网卡ip去访问,内网一般可以不配置bind,注释掉即可)
( 9) protected-mode no (关闭保护模式)
( 10) appendonly yes
如果要设置密码需要增加如下配置:
( 11) requirepass zhuge ( 设置redis访问密码)
( 12) masterauth zhuge ( 设置集群节点间访问密码,跟上面一致)
第三步:把修改后的配置文件,copy到8004,修改第2、3、4、6项里的端口号,可以用批量替换:
:%s/源字符串/目的字符串/g
第四步:另外两台机器也需要做上面几步操作,第二台机器用8002和8005,第三台机器用8003和8006
第五步:分别启动6个redis实例,然后检查是否启动成功
(1)/usr/local/redis-5.0.3/src/redis-server /usr/local/redis-cluster/800*/redis.conf
(2)ps -ef | grep redis 查看是否启动成功
第六步:用redis-cli创建整个redis集群( redis5以前的版本集群是依靠ruby脚本redis-trib.rb实现)
# 下面命令里的1代表为每个创建的主服务器节点创建一个从服务器节点
# 执行这条命令需要确认三台机器之间的redis实例要能相互访问,可以先简单把所有机器防火墙关掉,如果不关闭防火墙则需要打开redis服务端口和集群节点gossip通信端口16379(默认是在redis端口号上加1W)
# 关闭防火墙
# systemctl stop firewalld # 临时关闭防火墙
# systemctl disable firewalld # 禁止开机启动
# 注意:下面这条创建集群的命令大家不要直接复制,里面的空格编码可能有问题导致创建集群不成功
(1)/usr/local/redis-5.0.3/src/redis-cli -a zhuge --cluster create --cluster-replicas 1 192.168.0.61:8001 192.168.0.62:8002 192.168.0.63:8003 192.168.0.61:8004 192.168.0.62:8005 192.168.0.63:8006
第七步:验证集群:
(1)连接任意一个客户端即可:./redis-cli -c -h -p ( -a访问服务端密码,-c表示集群模式,指定ip地址和端口号)
如:/usr/local/redis-5.0.3/src/redis-cli -a zhuge -c -h 192.168.0.61 -p 800*
(2)进行验证: cluster info(查看集群信息)、cluster nodes(查看节点列表)
(3)进行数据操作验证
(4)关闭集群则需要逐个进行关闭,使用命令:
/usr/local/redis-5.0.3/src/redis-cli -a zhuge -c -h 192.168.0.60 -p 800* shutdown
引入依赖
1
2
3
4
5
<dependency>
<groupId> redis.clients</groupId>
<artifactId> jedis</artifactId>
<version> 2.9.0</version>
</dependency>
java 使用实例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
public class JedisClusterTest {
public static void main ( String [] args ) throws IOException {
JedisPoolConfig config = new JedisPoolConfig ();
config . setMaxTotal ( 20 );
config . setMaxIdle ( 10 );
config . setMinIdle ( 5 );
Set < HostAndPort > jedisClusterNode = new HashSet < HostAndPort > ();
jedisClusterNode . add ( new HostAndPort ( "192.168.0.61" , 8001 ));
jedisClusterNode . add ( new HostAndPort ( "192.168.0.62" , 8002 ));
jedisClusterNode . add ( new HostAndPort ( "192.168.0.63" , 8003 ));
jedisClusterNode . add ( new HostAndPort ( "192.168.0.61" , 8004 ));
jedisClusterNode . add ( new HostAndPort ( "192.168.0.62" , 8005 ));
jedisClusterNode . add ( new HostAndPort ( "192.168.0.63" , 8006 ));
JedisCluster jedisCluster = null ;
try {
//connectionTimeout:指的是连接一个url的连接等待时间
//soTimeout:指的是连接上一个url,获取response的返回等待时间
jedisCluster = new JedisCluster ( jedisClusterNode , 6000 , 5000 , 10 , "zhuge" , config );
System . out . println ( jedisCluster . set ( "cluster" , "zhuge" ));
System . out . println ( jedisCluster . get ( "cluster" ));
} catch ( Exception e ) {
e . printStackTrace ();
} finally {
if ( jedisCluster != null )
jedisCluster . close ();
}
}
}
引入依赖
1
2
3
4
5
6
7
8
9
<dependency>
<groupId> org.springframework.boot</groupId>
<artifactId> spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId> org.apache.commons</groupId>
<artifactId> commons-pool2</artifactId>
</dependency>
配置链接信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
server :
port : 8080
spring :
redis :
database : 0
timeout : 3000
password : zhuge
cluster :
nodes : 192.168.0.61 : 8001 , 192.168.0.62 : 8002 , 192.168.0.63 : 8003 , 192.168.0.61 : 8004 , 192.168.0.62 : 8005 , 192.168.0.63 : 8006
lettuce :
pool :
max-idle : 50
min-idle : 10
max-active : 100
max-wait : 1000
使用代码
1
2
3
4
5
6
7
8
9
10
11
12
@RestController
public class IndexController {
private static final Logger logger = LoggerFactory . getLogger ( IndexController . class );
@Autowired
private StringRedisTemplate stringRedisTemplate ;
@RequestMapping ( "/test_cluster" )
public void testCluster () throws InterruptedException {
stringRedisTemplate . opsForValue (). set ( "zhuge" , "666" );
System . out . println ( stringRedisTemplate . opsForValue (). get ( "zhuge" ));
}
}
Redis Cluster 将所有数据划分为 16384 个 slots(槽位),每个节点负责其中一部分槽位。槽位的信息存储于每个节点中。当 Redis Cluster 的客户端来连接集群时,它也会得到一份集群的槽位配置信息并将其缓存在客户端本地。这样当客户端要查找某个 key 时,可以直接定位到目标节点。同时因为槽位的信息可能会存在客户端与服务器不一致的情况,还需要纠正机制来实现槽位信息的校验调整。
槽位定位算法
Cluster 默认会对 key 值使用 crc16 算法进行 hash 得到一个整数值,然后用这个整数值对 16384 进行取模来得到具体槽位。HASH_SLOT = CRC16(key) mod 16384
Redis之所以快是因为:1、基于内存操作,2-单线程没有上下文切换,3.基于epoll事件分发模型。所有的连接都放在一个队列里,注册到事件分发器上,如果有客户端发送数据,分发器或通知线程处理。
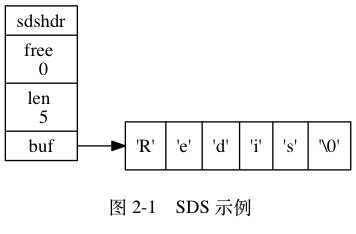
Redis 没用使用C自带的字符串,二是自己定义一个,成为sds简单动态字符串。
1
2
3
4
5
6
7
8
9
struct sdshdr {
// 记录 buf 数组中已使用字节的数量
// 等于 SDS 所保存字符串的长度
int len ;
// 记录 buf 数组中未使用字节的数量
int free ;
// 字节数组,用于保存字符串
char buf [];
}
比起 C 字符串, SDS 具有以下优点
常数复杂度获取字符串长度, O(1)。
杜绝缓冲区溢出,预先扩容,惰性缩容。
减少修改字符串长度时所需的内存重分配次数。
二进制安全。
兼容部分 C 字符串函数。
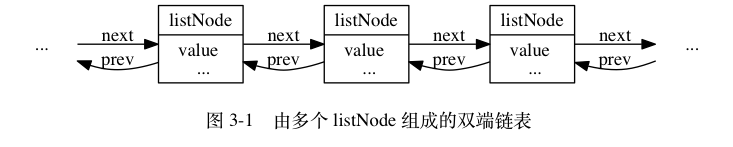
链表提供了高效的节点重排能力, 以及顺序性的节点访问方式, 并且可以通过增删节点来灵活地调整链表的长度。每个链表节点使用一个 adlist.h/listNode 结构来表示 ,多个 listNode 可以通过 prev 和 next 指针组成双端链表。
1
2
3
4
5
6
7
8
typedef struct listNode {
// 前置节点
struct listNode * prev ;
// 后置节点
struct listNode * next ;
// 节点的值
void * value ;
} listNode ;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
typedef struct list {
// 表头节点
listNode * head ;
// 表尾节点
listNode * tail ;
// 链表所包含的节点数量
unsigned long len ;
// 节点值复制函数
void * ( * dup )( void * ptr );
// 节点值释放函数
void ( * free )( void * ptr );
// 节点值对比函数
int ( * match )( void * ptr , void * key );
} list ;
用途:链表被广泛用于实现 Redis 的各种功能, 比如列表键, 发布与订阅, 慢查询, 监视器, 等等。
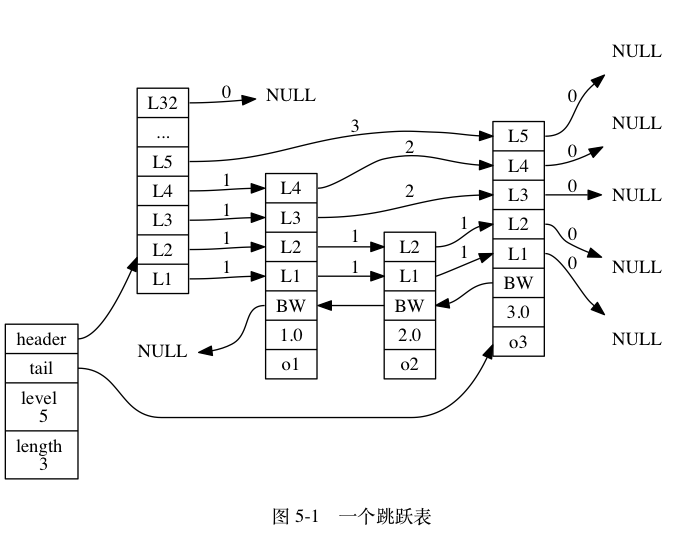
Redis 的有序集合是用跳跃表实现的,跳跃表(skiplist)是一种有序数据结构, 它通过在每个节点中维持多个指向其他节点的指针, 从而达到快速访问节点的目的,跳跃表由 redis.h/zskiplistNode 和 redis.h/zskiplist 两个结构定义。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
typedef struct zskiplistNode {
// 后退指针
struct zskiplistNode * backward ;
// 分值
double score ;
// 成员对象
robj * obj ;
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode * forward ;
// 跨度
unsigned int span ;
} level [];
} zskiplistNode ;
1
2
3
4
5
6
7
8
typedef struct zskiplist {
// 表头节点和表尾节点
struct zskiplistNode * header , * tail ;
// 表中节点的数量
unsigned long length ;
// 表中层数最大的节点的层数
int level ;
} zskiplist ;
图 5-1 展示了一个跳跃表示例, 位于图片最左边的是 zskiplist 结构, 该结构包含以下属性:
header :指向跳跃表的表头节点。tail :指向跳跃表的表尾节点。level :记录目前跳跃表内,层数最大的那个节点的层数(表头节点的层数不计算在内)。length :记录跳跃表的长度,也即是,跳跃表目前包含节点的数量(表头节点不计算在内)。
描述:查询了根本不存在的数据,导致请求打倒数据库。产生原因:自身业务代码或数据问题、恶意攻击、爬虫。
解决方案:1.缓存空对象。2.布隆过滤器。功能:布隆过期中不存在的对象一定不存,存在的不一定存在;特点:只能加数据数据,不能删数据。需要预先把所有数据初始化到布隆过滤器;Redis对应的产品:Redison。
描述:同一时间大量缓存失效导致请求直达数据库,造成数据库压力过大。
解决方案:在设置过期时间时加上一个随机值。
描述:缓存无法支持大量请求宕机,请求全部打到数据库。
解决方案:1.使用缓存高可用架构,如:Redis Sentinel 或 Redis Cluster。2.使用限流熔断并降级,如:Sentinel或Hystrix。3.提前演练,模拟宕机后做出一些应对情况。
描述:热点缓存失效,重建又比较好耗时,出现这种情况时大量请求会直达后端,有大量线程重建缓存,会造成后端压力过大。
解决方案:加一个分布式锁,只允许一个缓存重建缓存。
描述:在并发情况同时操作数据库和缓存可能导致缓存与数据库不一致。
解决方案:1.大部分场景是容忍短时间内缓存与数据库不一致的,只有设置过期时间即可,不能容忍不一致的可以加读写锁实现,但会牺牲一定的性能。
 telzhou618 收录于 db 中间件
telzhou618 收录于 db 中间件